Data collection + Evaluation และการจัดเก็บข้อมูลและการวิเคราะห์ข้อมูลก่อนนำไปใช้ในการเทรน AI
หากทุกท่านได้ติดตามบทความในตอนแรกไปแล้วที่มีชื่อว่า สรุปคู่มือออกแบบ AI จาก People + AI โดย Google (ตอน 1) เราได้พูดถึงเรื่องของ User Needs + Defining Success การตามหาความต้องการของผู้ใช้งานและการวัดผลความสำเร็จของโปรเจค AI ที่เราต้องการจัดทำ
ในบทความตอนที่สองนี้ เราจะมาต่อกันที่หัวข้อของ Data Collection + Evaluation วิธีการจัดเก็บข้อมูลและการวิเคราะห์ข้อมูล ดูว่าเราต้องการข้อมูลส่วนไหนบ้างที่สอดคล้องกับความต้องการของ User ของเรา
หมายเหตุ บทความนี้จะเหมาะสำหรับคนที่ทำงาน UX และ คนที่ทำงานฝั่ง Data เพื่อจัดเตรียมข้อมูลก่อนจะนำไปใช้งานในขั้นถัดไป โดยบทนี้มีคำศัพท์ที่ Jargon อยู่พอสมควร สำหรับมือใหม่มีคำแนะนำว่าให้ลองอ่านคำอธิบายในวงเล็บประกอบได้เลยนะคะ
- User Needs + Defining Success
- Data Collection + Evaluation
- Mental Models
- Explainability + Trust
- Feedback + Control
- Error + Graceful Failure

Data Collection + Evaluation
ในเนื้อหาตอนสองนี้ จะประกอบไปด้วยเรื่องของ
- Dataset ของเรามีฟีเจอร์เพียงพอที่จะทำให้ AI ของเราตรงกับความต้องการของ Users หรือไม่ ?
- เราควรใช้ Dataset ที่มีอยู่แล้วในตลาดเอามาฝึก AI ของเรา หรือว่าจะคิดค้นพัฒนาขึ้นมาใหม่เอง ?
- เราจะมั่นใจได้อย่างไรว่าคนที่จะสอน Machine learning (Raters) จะไม่สอดแทรกข้อมูลที่ผิดพลาดหรือไบแอสไปที่ datasets ที่เรามีอยู่ตอนกำหนด labels ?
เรื่องที่ควรรู้เมื่อทำงานกับ AI
ขั้นตอนที่จะเริ่มการทำนายผล AI-driven products นั้นเราจะต้องเข้าใจก่อนว่า Machine learning model ของเราจะต้องจดจำ Pattern และ Correlations ประเภทต่าง ๆ ใน Data ของเราให้ได้เสียก่อน โดยตัว Data ที่เรากล่าวถึงนี้จะมีชื่อเรียกที่คนใช้งานกันว่าเทรนนิ่งดาต้า (Training data)
ตัวเทรนนิ่งดาต้าสามารถจัดเก็บเป็น รูปภาพ, วิดีโอ, ตัวหนังสือ, ไฟล์เสียง และอื่น ๆ ได้ โดยเราสามารถใช้ของที่เรามีอยู่เหล่านี้ หรือจะเก็บข้อมูลมาใหม่ก็ได้เพื่อนำมาใช้ในการเทรนตัวโมเดลของเรา ตัวอย่างเช่น อาจจะใช้ database รูปภาพสุนัขจากสถานที่อุปการะสุนัขมาใช้ในการเทรนโมเดลเพื่อให้โมเดลสามารถจดจำลักษณะและแยกประเภทของสุนัขแต่ละพันธุ์ได้
โดยข้อมูลที่เราจัดเก็บมานั้นหรือ data ที่เราทำ label (label คือการตั้งชื่อที่อธิบายถึงตัว Data นั้น ๆ) ไว้แล้ว จะหมายถึงข้อมูล output สิ่งที่จะออกมาจากระบบเราด้วย
การคิดเรื่องของ Data และการเทรนข้อมูลนั้นจะไม่สามารถเกิดขึ้นได้ ถ้าหากว่าเรายังไม่ผ่านขั้นตอนการคิดแบบ Human-centred design (จากตอนที่ 1) เพราะถ้าเราสร้าง AI ขึ้นมาโดยที่ไม่มีความต้องการของ user แล้วล่ะก็ การทำ AI ออกมานั้นก็จะไร้ประโยชน์ สร้างเสร็จแล้วก็อาจจะไม่มีผู้ใช้งานของเรา นั่นจึงเป็นเหตุผลที่เราจะต้องมาเรียนรู้กันต่อในตอนที่ 2 ว่าด้วยเรื่องของการแปลข้อมูลความต้องการของผู้ใช้งานออกมาเป็น dataset ที่จะสามารถนำมาใช้เทรน AI ของเราได้
สิ่งที่เราต้องถามตัวเองในบทที่ 2 นี้ก็คือ
- ความต้องการของ User ตรงกับผลลัพธ์ของ AI ที่เราจะทำหรือไม่ (Align) ?
- ผลลัพธ์ของ AI นั้นมีความเชื่อมโยงกับ dataset ที่เราจะใช้เทรน AI หรือไม่ (Map) ?
- Dataset ที่เราจะใช้นั้น เราจะเอาข้อมูลมาจากไหน (Source) ?
โดยข้อมูลนั้นจะต้องไม่มีความ bias, มีความหลากหลาย, มีความสมบูรณ์เพียงพอที่จะเอาไปเทรนโมเดลต่อได้ - จะปรับจูน AI โมเดลอย่างไรให้ได้ผลลัพธ์ที่ตรงกับความต้องการผู้ใช้งาน (Tune) ?
➀ ตีความหมาย User needs ให้เป็น Data ที่เราต้องการจะใช้งาน
ความต้องการของ User ตรงกับผลลัพธ์ของ AI ที่เราจะทำหรือไม่ (Align) ?
ขั้นตอนนี้เป็นขั้นตอนที่เราจะตีความหมายที่เราได้มาจากการทำรีเสิชในครั้งที่แล้ว อาจจะใช้เวลาไม่กี่ชั่วโมงในการทำ ด้วยวิธีการลงไปนั่งคุยกับทีมของเราที่ทำรีเสิชมาแล้ว กางดูในหลาย ๆ มุมมองว่าเป้าหมายที่แท้จริงของ user ของเราคืออะไร ใครจะเป็นคนใช้งานกันแน่ กลุ่มเป้าหมาย แล้วก็ต้องคิดถึงไปเรื่องของ AI outputs ผลลัพธ์เป้าหมายที่เราต้องการที่จะตอบโจทย์กับความต้องการนั้น
กลับมาที่โปรเจค Google flights ของเรา
สิ่งที่ User ต้องการทราบมากที่สุดคือ “เวลาที่ฉันจะต้องจองตั๋วเครื่องบิน“
“ราคามันจะขึ้นไปอีกมั้ยพรุ่งนี้ หรือว่าจะรอก่อนแล้วจะจ่ายทีหลัง”
ดังนั้นผลลัพธ์ของ AI (AI output) จึงต้องแสดงผลดังนี้
- ราคาที่ดีที่สุดในปัจจุบัน
- การคำนวนราคาในอนาคต
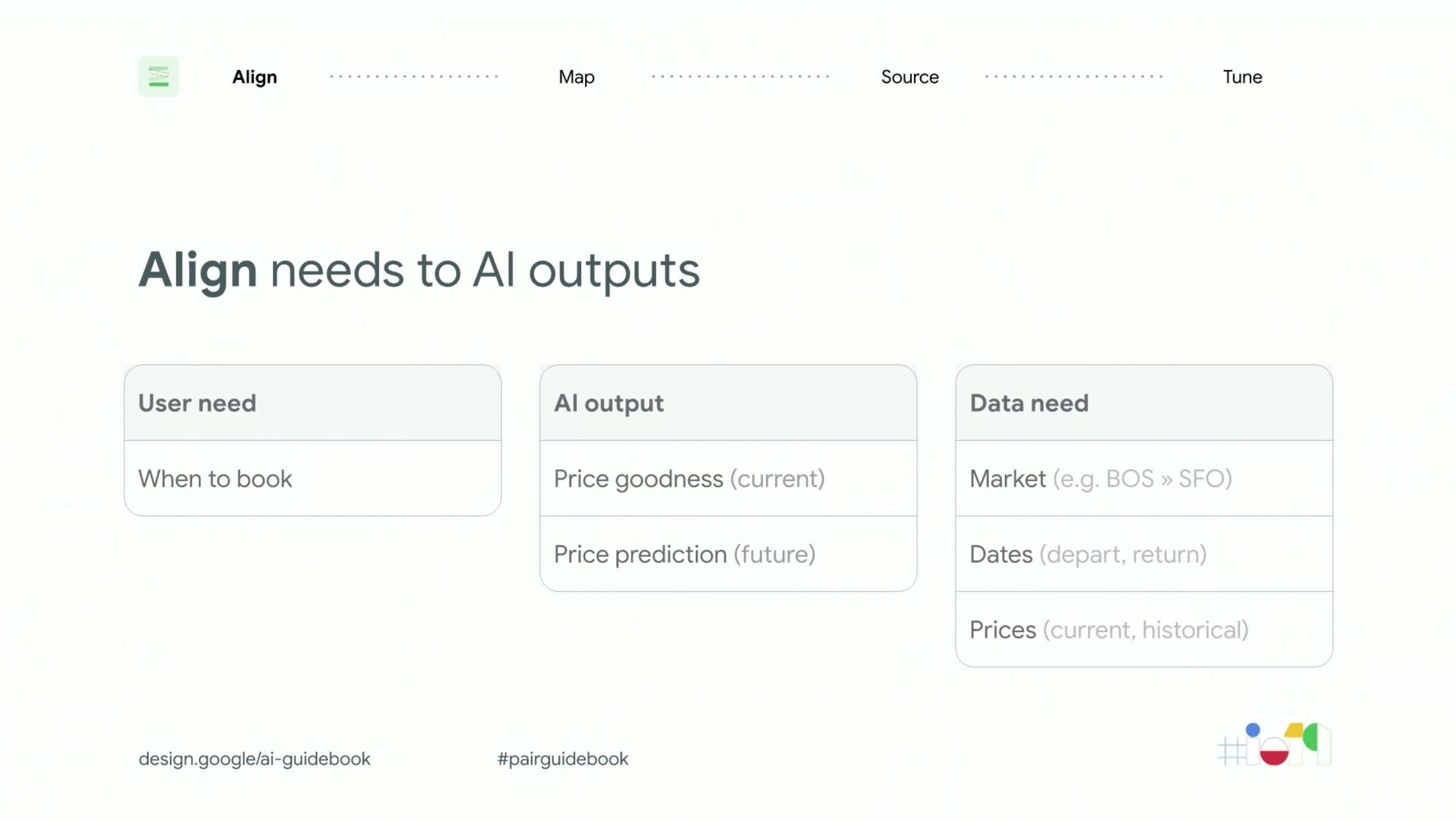
แต่การที่ AI จะได้ผลลัพธ์ที่ตอบโจทย์กับความต้องการ User ได้ดีนั้น AI จะต้องเข้าใจก่อนว่าราคาในปัจจุบันนั้นอยู่ที่เท่าไร ต่ำ, ปานกลาง หรือว่าราคาตอนนี้สูงที่สุดอยู่ แล้วในอนาคตล่ะ จะขึ้น, ลงหรือว่าเท่าเดิม
➁ ผลลัพธ์ของ AI นั้นมีความเชื่อมโยงกับ dataset ที่เราจะใช้เทรน AI หรือไม่ (Map) ?
สำหรับคนที่เคยทำงานกับ Machine learning มาแล้วเนี่ย เราจะต้องคิดถึงเรื่องของ Structured data (ข้อมูลเชิงโครงสร้าง) ก่อนการนำไปใช้งาน ถ้าอธิบายคำนี้เพิ่มเติมอีกนิดนึง Structured data ก็คือข้อมูลแบบตารางที่มีการจัดเรียงอย่างมีรูปแบบชัดเจนและเป็นระเบียบ สามารถนำมาใช้วิเคราะห์ได้เลย
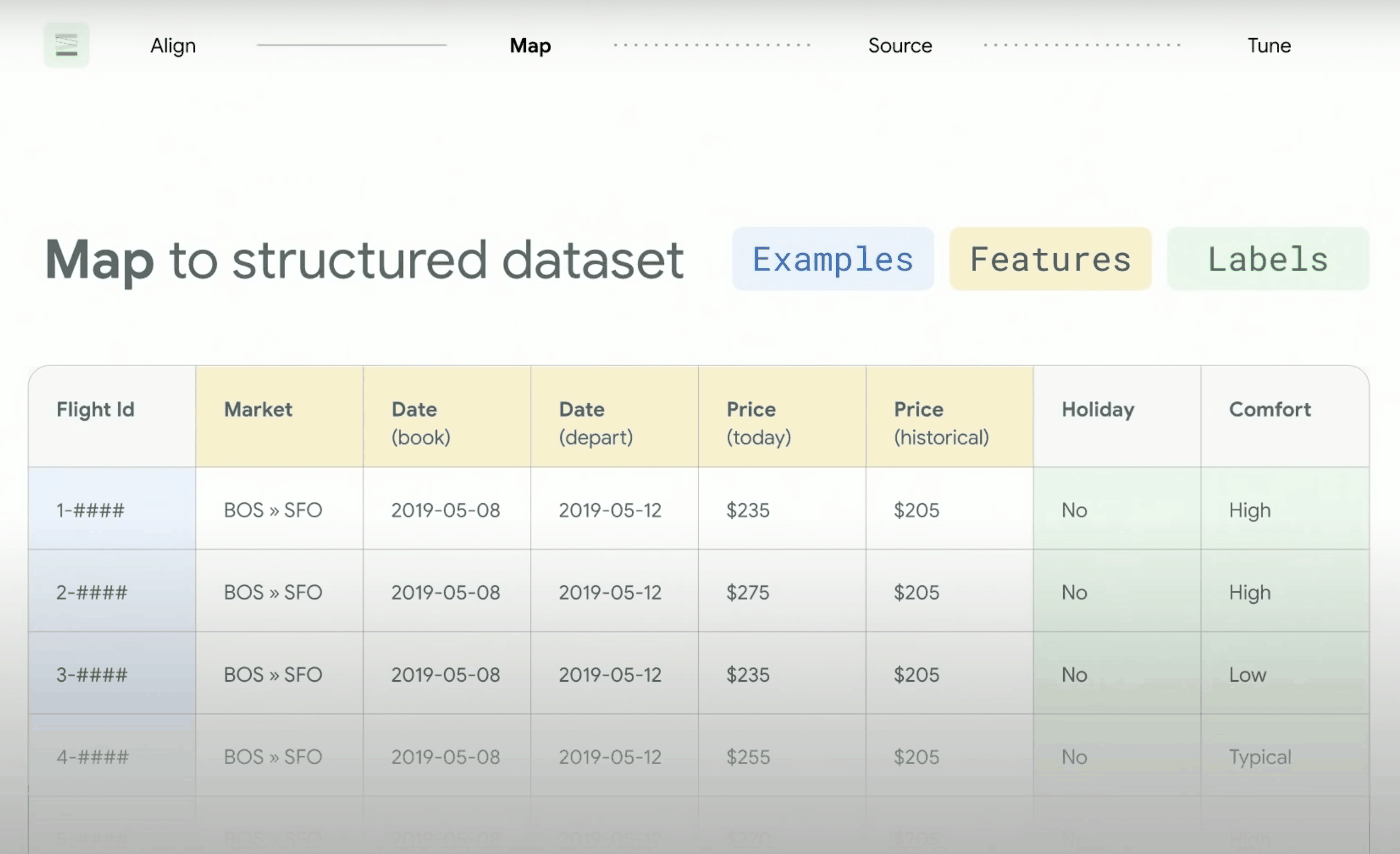
โดยการใช้ข้อมูลแบบ Structured data ค่อนข้างเป็นที่นิยมในการนำไปใช้เทรนโมเดลประเภท Supervised learning
Structured datasets จะประกอบไปด้วย
- Examples คือแถวของข้อมูลที่สำคัญที่สุด (สีฟ้า)
- ในแต่ละ Example จะประกอบไปด้วย Features (สีเหลือง)
คือข้อมูลที่ถูกจัดเรียงให้เป็นหมวดหมู่อยู่ใน Categories แล้วเรียบร้อย - Labels จะเป็นข้อมูลประเภท Qualitative (ข้อมูลเชิงคุณภาพ) ส่วนใหญ่จะถูกสร้างมาโดยมนุษย์ (สีเขียว)
➂ Dataset ที่เราจะใช้นั้น เราจะเอาข้อมูลมาจากไหน (Source) ?
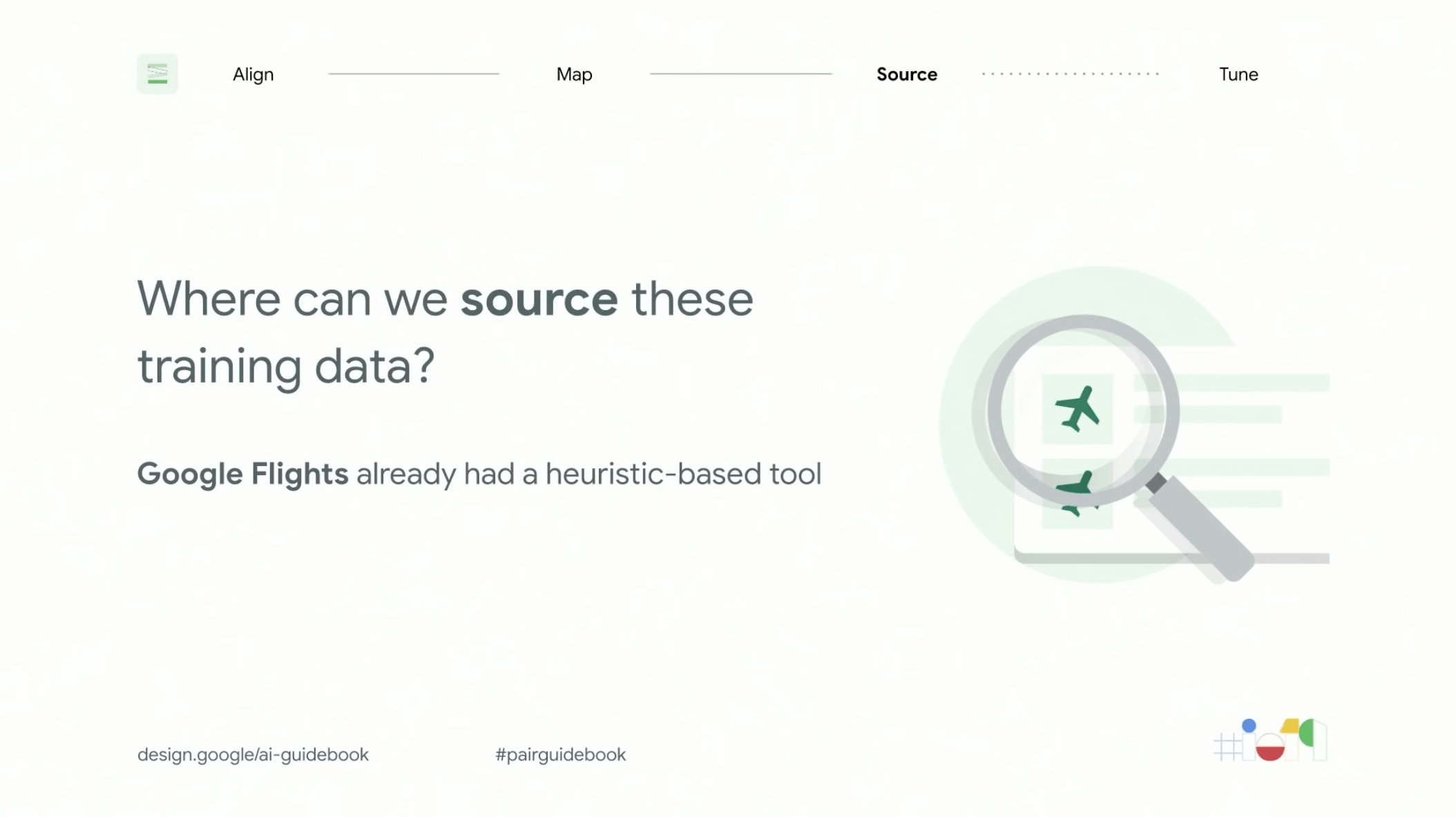
กลับมาที่คำถามว่า แล้วถ้าเราจะเริ่มเทรนข้อมูล เราจะเอาข้อมูลจากไหนมาใช้งานกันนะ
สำหรับหลาย ๆ คน อาจจะไม่ได้มีข้อมูลที่มีจำนวนมากเหมือนกับที่ Google มี อ้าว แล้วทีนี้จะเอามาจากไหนกันล่ะ
ดังนั้นเราจึงจะต้องย้อนมาถามตัวเองก่อนทุกครั้งว่า ข้อมูลของเรามีอะไรที่น่าเป็นห่วงหรือไม่ด้วยคำถามดังต่อไปนี้
- มี dataset ที่เปิดให้ใช้งานแบบ public หรือไม่ ? หรือว่าเราจะต้องสร้างขึ้นมาเองใหม่ทั้งหมด
- dataset ที่เรามีแล้ว มีความหลากหลาย (diversity) ที่เพียงพอที่จะได้ผลลัพธ์ที่ user ต้องการหรือไม่ ?
ตัวอย่างเช่น ถ้าเราจะทำ Google flights เรามีข้อมูลสายการบินทั่วโลกมากพอหรือเปล่า เรารู้มั้ยว่าสายการบินนี้ขึ้นจากไหนไปไหน วันไหน ราคาเท่าไร ระยะทาง ซื้อตั๋วเวลาไหน etc. - dataset ของเรามีเรื่องที่ต้องกังวลเรื่องของ privacy มั้ย, มี bias หรือเปล่า, ถูกต้องหรือไม่ ?
Google pairs team ยังมี tips และคลังข้อมูลจำนวนมากสำหรับการเตรียม Dataset มีเครื่องมือแนะนำด้วย Facets – Know your data
➃ จะปรับจูน AI โมเดลอย่างไรให้ได้ผลลัพธ์ที่ตรงกับความต้องการผู้ใช้งาน (Tune) ?
ขั้นตอนนี้จะเป็นขั้นตอนการปรับจูนตัว data คือการแก้ไขปรับเปลี่ยนข้อมูลให้เกิดความแม่นยำและเชื่อถือได้มากที่สุด
Google แนะนำหลักการคิดแบบภาพด้านล่างเข้ามาช่วยเช็คว่าข้อมูลของเรานั้นดีหรือยัง เพื่อให้ตอบโจทย์กับผู้ใช้งานมากที่สุดตามหลักของ Human centred design
คือ ถ้าการวัดผล [Metric] จาก [AI Tool] [มีอะไรที่สูงกว่าหรือต่ำกว่าระดับที่วางไว้] จะ [ทำอะไรสักอย่าง]
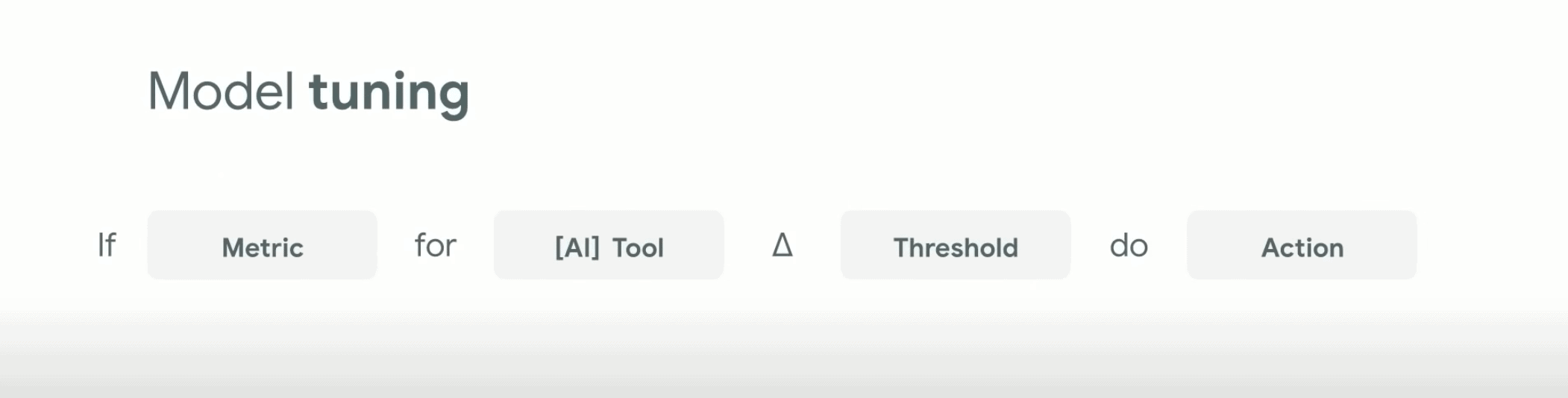
ตัวอย่างเช่น Flight insights
ถ้าเกิดว่าการวัดผลเรื่อง “การจองตั๋วเครื่องบิน” จากทูลที่ชื่อว่า “Flights insight” “มีคะแนนที่ลดลงต่ำกว่า X%” (คนก็จะเลิกใช้งานระบบนี้แน่ ๆ) ดังนั้นเราจึงจะต้องทำอะไรสักอย่างเพื่อให้ user เกิดความมั่นใจในข้อมูลมากยิ่งขึ้น

สรุป
สิ่งที่ทีม Data ทำในการจัดเตรียมข้อมูลเพื่อนำไปเทรน AI นั้นมีดังต่อไปนี้คือ
- ปรับผลลัพธ์ของ AI ให้ตรงกับความต้องการของ Users (Align)
- ปรับ dataset เพื่อให้ตรงกับเป้าหมายของเรา (Map)
- มีชุดข้อมูล Dataset ที่ไม่มีความ bias, มีความหลากหลาย, และมีความสมบูรณ์เพียงพอที่จะเอาไปเทรนโมเดลต่อได้ (Source)
- ปรับจูน AI โมเดลให้ตรงกับเป้าหมายของผู้ใช้งาน (Tune)

ในปัจจุบันตัวไฟล์ของ Pairs จะมีเพิ่มขั้นตอนมาอีกสอง 2 ก็จะเป็นทั้งหมด 6 ข้อ จะเพิ่มจากวิดีโอที่สรุปมาอีกนิดหน่อย
ดังนั้นเพื่อน ๆ สามารถอ่านข้อมูลฉบับเต็มล่าสุดได้จาก Pair.withgoogle.com เลยนะคะ :)
บทความนี้ต้องบอกเลยว่ามีคำศัพท์ที่ซับซ้อนและแปลกใหม่อยู่เยอะแยะเต็มไปหมด อาจจะต้องใช้เวลาในการทำความเข้าใจพอสมควรสำหรับคนที่ไม่คุ้นชินเรื่องของ Data collection มาก่อน
หวังว่าเพื่อน ๆ จะได้ความรู้ตั้งแต่บทความที่หนึ่งไปจนถึงบทความที่สองเลย ถ้าอยากให้เราเขียนเรื่องอะไร นำเสนอมาได้ในผ่านทางแชทของแฟนเพจ Designil ได้เลยนะคะ แอดจะพยายามมาให้เขียนให้แบบเข้าใจง่าย ๆ แบบนี้อีก แล้วเจอกันใหม่บทความหน้าค่า
บทความที่เกี่ยวข้อง
- สรุปคู่มือออกแบบ AI จาก People + AI โดย Google (ตอน 1)
- เคสการออกแบบ Spotify ที่ใช้ข้อมูล Data Science + UX
- เคสการทำ Personalization และ AI ของ LinkedIn
- รีวิว 10 คอร์สเรียน UX จาก Coursera เทคโนโลยีใหม่ๆ เพียบ
- 10 สุดยอดคอร์สเรียนออนไลน์เพื่ออาชีพในอนาคต
ข้อมูลจาก